
1、 创建一个job实例
Job job=Job.getInstance(conf);
job.waitForCompletion(true);2、 进入waitForCompletion()方法
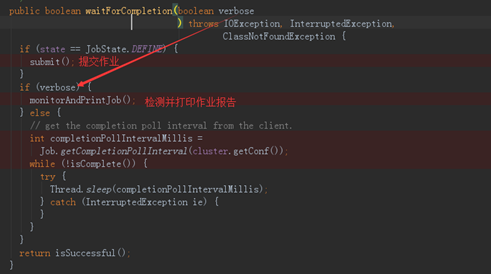
3、 当JobState为define时,则提交作业,进入submit方法
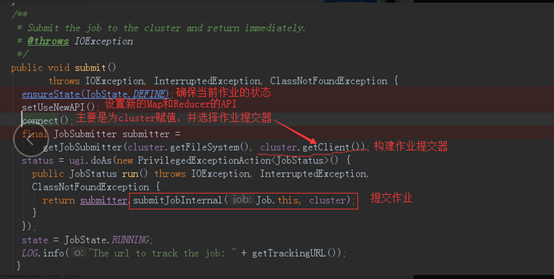
4、 进入connect()方法中。代码主要如下
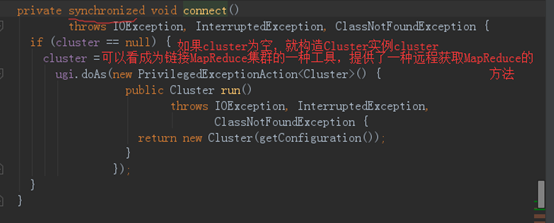
5、进入return的Cluster(getConfiguration())方法。看下Cluster的几个主要成员
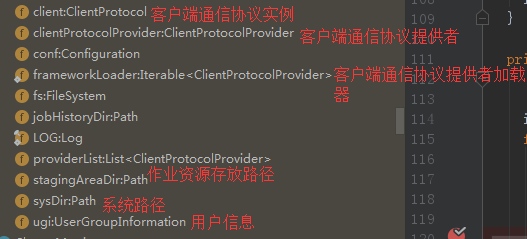
Cluster最重要的两个成员变量是客户端通信协议提供者ClientProtocolProvider实例clientProtocolProvider和客户端通信协议ClientProtocol实例client,而后者是依托前者的create()方法生成的。Cluster类提供了两个构造函数,如下: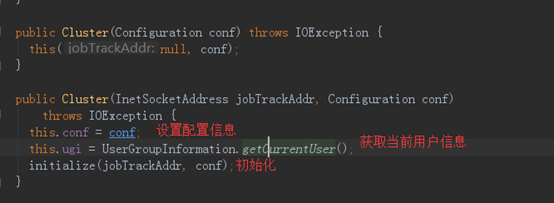
6、在Cluster构造方法中最后一步initialize(jobTrackAddr,conf);会先加载通信协议提供者列表,然后对其遍历,会先遍历到LocalClientProtocolProvider,如果clientProtocol的值不为null,就对Cluster的成员clientProtocolProvider和client赋值,break调出循环;如果clientProtocol的值为null,则进行下一次循环。
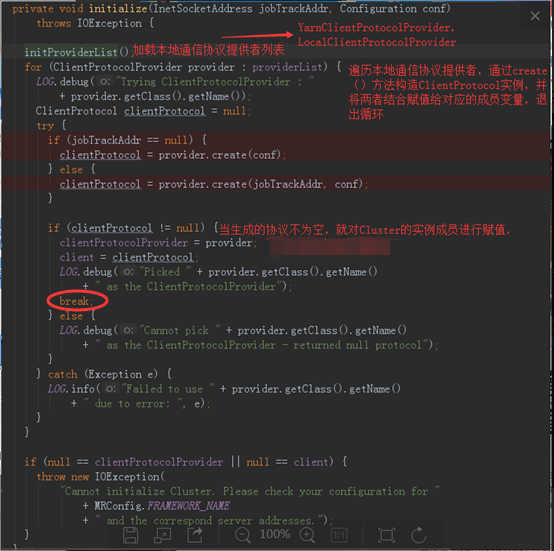
当我用本地模式调试时,provider=LocalClientProtocolProvider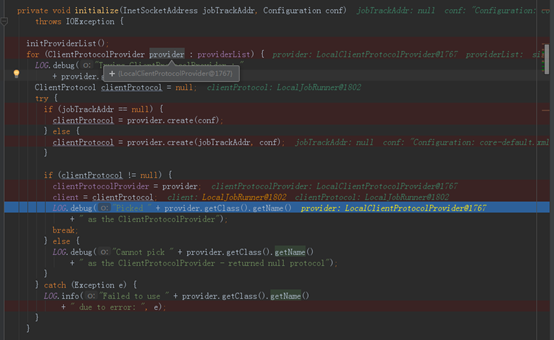
7、上面再说create()方法时已经提到了两种ClientProtocolProvider实现类,后来通过查阅资料得知了更加确切的说法:MapReduce中,ClientProtocolProvider抽象类的实现共有YarnClientProtocolProvider、LocalClientProtocolProvider两种,前者为Yarn模式,而后者为Local模式。
看下Local模式,LocalClientProtocolProvider的create()方法,代码如下:
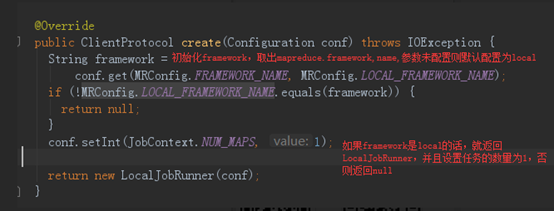
由上可知,MapReduce需要看参数mapreduce.framework.name确定连接模式,但默认是Local模式的。
再来看Yarn模式,看下YarnClientProtocolProvider的create()方法,代码如下: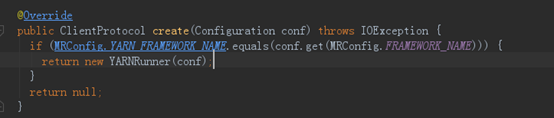
8、 到了这里,我们就能够知道一个很重要的信息,Cluster中客户端通信协议ClientProtocol实例,要么是Yarn模式下的YARNRunner,要么就是Local模式下的LocalJobRunner。
· 以Yarn模式来分析MapReduce集群连接,看下YARNRunner的实现,先看下它的成员变量,如下:
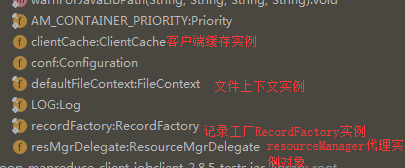
其中,最重要的一个变量就是ResourceManager的代理ResourceMgrDelegate类型的resMgrDelegate实例,Yarn模式下整个MapReduce客户端就是由它负责与Yarn集群进行通信,完成诸如作业提交、作业状态查询等过程,通过它获取集群的信息,其内部有一个YarnClient实例YarnClient,负责与Yarn进行通信,还有ApplicationId、ApplicationSubmissionContext等与特定应用程序相关的成员变量。以后有时间还要详细介绍这个对象。另外一个比较重要的变量就是客户端缓存ClientCache实例clientCache。
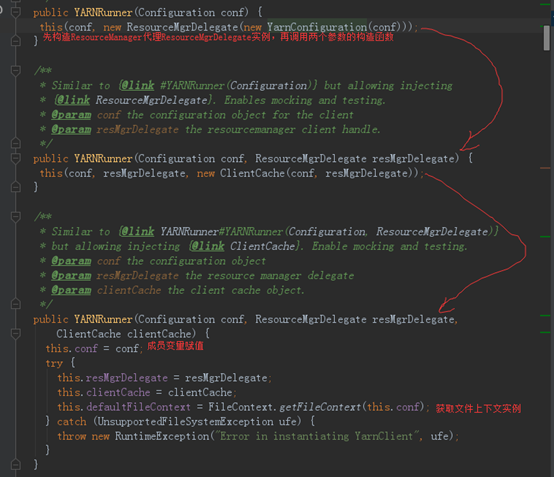
YARNRunner一共提供了三个构造函数,而我们之前说的WordCount作业提交时,其内部调用的是YARNRunner带有一个参数的构造函数,它会先构造ResourceManager代理ResourceMgrDelegate实例,然后再调用两个参数的构造函数,继而构造客户端缓存ClientCache实例,然后再调用三个参数的构造函数,而最终的构造函数只是进行简单的类成员变量赋值,然后通过FileContext的静态getFileContext()方法获取文件山下文FileContext实例defaultFileContext。
· 本地模式分析LocalJobRunner:对LocalJobRunner实例调用submitJob( )方法会创建Job(LocalJobRunner的内部类)实例,该实例完成作业的执行。
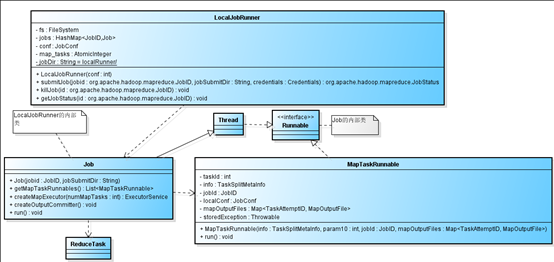
LocalJobRunner的内部类Job就是一个线程,其实本地模式的MapReduce作业就由该线程完成。Job的内部类MapTaskRunnable实现了Runnable接口,代表了Map任务,每个分片都对应一个MapTaskRunnable实例,Job采用java并发包提供的ExecutorService线程池来执行MapTaskRunnable实例,线程池的大小为分片数量和mapreduce.local.map.tasks.maximum配置项值中较小者,至少为1。线程池创建好之后就将MapTaskRunnable实例都提交到其中去执行,然后线程池停止接受新任务等待线程执行完毕。线程执行完毕后会逐个检查MapTaskRunnable实例有没有异常出现,如果有则认为map执行失败,直接抛出异常终止执行,如果都没有异常则认为map都执行成功,接下来继续执行reduce。本地模式值允许0个或者1个reduce任务。ReduceTask代表一个reduce任务,它从map的输出文件中读取数据进行reduce操作,将结果写到指定的目录中。reduce任务执行完之后,会进行一些清理操作,删除map的中间输出,删除作业提交目录和其中的作业配置文件、删除作业的本地拷贝文件等。
9、 connect()方法总结
MapReduce作业提交时连接集群是通过Job的connect()方法实现的,它实际上是构造集群Cluster实例cluster。Cluster为连接MapReduce集群的一种工具,提供了一种获取MapReduce集群信息的方法。在Cluster内部,有一个与集群进行通信的客户端通信协议ClientProtocol实例client,它由ClientProtocolProvider的静态create()方法构造,而Hadoop2.8.5中提供了两种模式的ClientProtocol,分别为Yarn模式的YARNRunner和Local模式的LocalJobRunner,Cluster实际上是由它们负责与集群进行通信的,而Yarn模式下,ClientProtocol实例YARNRunner对象内部有一个ResourceManager代理ResourceMgrDelegate实例resMgrDelegate,Yarn模式下整个MapReduce客户端就是由它负责与Yarn集群进行通信,完成诸如作业提交、作业状态查询等过程,通过它获取集群的信息。
10、运行完connect方法后执行submitJobInternal(Job.this, cluster);
该方法隶属于JobSubmitter类,顾名思义,该类是MapReduce中作业提交者,而实际上JobSubmitter除了构造方法外,对外提供的唯一一个非private成员变量或方法就是submitJobInternal()方法,它是提交Job的内部方法,实现了提交Job的所有业务逻辑。
首先,我们先看下JobSubmitter的类成员变量,如下:
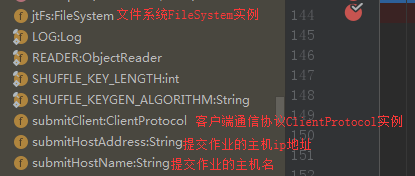
它一共有四个类成员变量,分别为:
1、 文件系统FileSystem实例jtFs:用于操作作业运行需要的各种文件等;
2、客户端通信协议ClientProtocol实例submitClient:用于与集群交互,完成作业提交、作业状态查询等,上文已经介绍过了。
3、提交作业的主机名submitHostName;
4、提交作业的主机地址submitHostAddress。
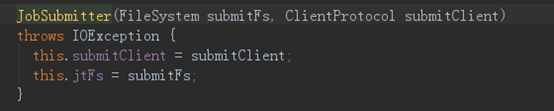
接下来,我们再看下JobSubmitter的构造函数,如下:
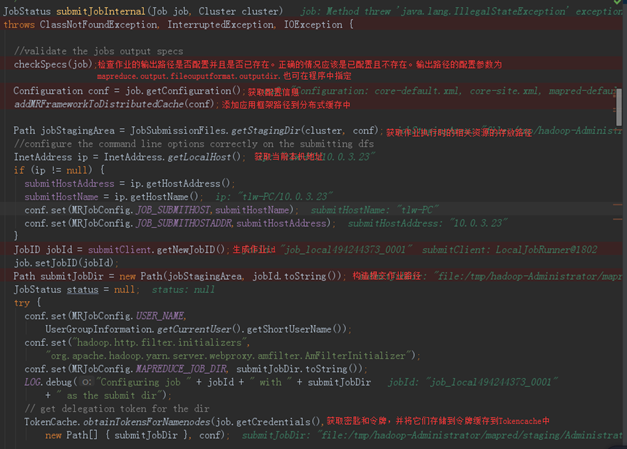
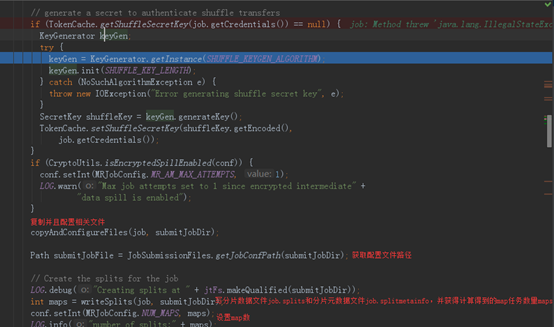
接下里是最重要的代码——JobSubmitter唯一的对外核心功能方法submitJobInternal(),它被用于提交作业至集群,代码如下:
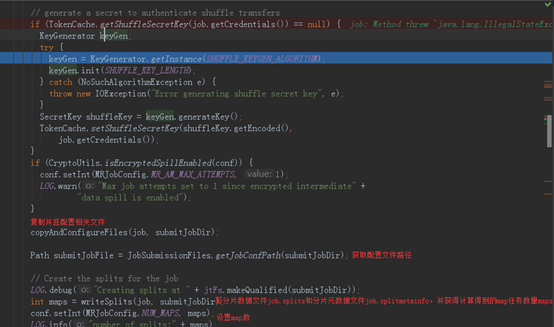
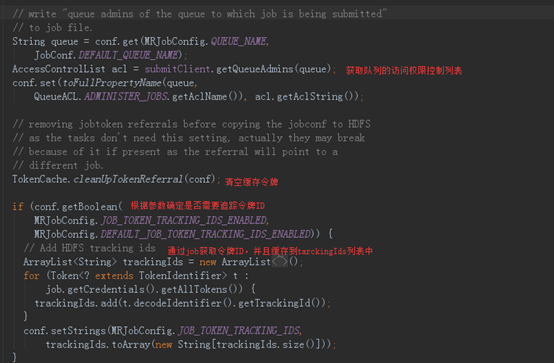
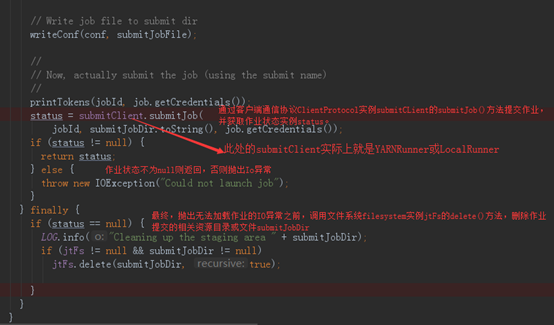
MapReducer的作业提交大致过程就这样了。